
リード
こんにちは、ぽまらのです。
AIエージェント勉強記 の 第2回 です。
索引 「AIエージェントを自分で作る — 勉強記シリーズ」 · 第1回 でエージェントの基本概念を整理しました。
この回は サンプル題材 — X(@syouwanotaisyou) 向けの日本語投稿文案 — を題材に、文案エージェント と 校正エージェント の 2体設計 を書きます。
「なぜ1体ではなく2体か」「それぞれの責務」「連携の順序」「評価のチェックリスト」までを設計段階で固定します。実装と比較実験は 第3回 です。
この回の全体像
flowchart LR P1["第1回<br/>概念"] D1["設計<br/>文案の責務"] D2["設計<br/>校正の責務"] D3["6項目<br/>チェックリスト"] P3["第3回<br/>比較実験"] P1 --> D1 --> D2 --> D3 --> P3 classDef meta fill:#eceff1,stroke:#607d8b,stroke-width:2px,color:#1a1a1a classDef concept fill:#e8f4fc,stroke:#3d7ea6,stroke-width:2px,color:#1a1a1a classDef agent fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px,color:#1a1a1a class P1 meta class D1 concept class D2 agent class D3 agent class P3 meta

なぜこのサンプルか
| 理由 | 説明 |
|---|---|
| ルールが明確 | 140字・2文構成・禁止表現など 合格/不合格が判定しやすい |
| 半自動で現実的 | 投稿は人間 — X半自動運用記事 と同じ方針 |
| 既に文案 spec がある | x-shuuchaku-agent-spec.md を文案側の正本にできる |
| 校正の効果を測れる | 文字数超過など 再現しやすい失敗 がある |
テーマは 内省テック — 仏教の教えと日常の小さな実践を短く発信するブランドです。
1体だけだと何が起きやすいか
文案エージェント だけ で運用すると、次の失敗が起きやすくなります。
| 失敗パターン | 例 |
|---|---|
| 文字数超過 | spec に「140字」とあっても 200字超の文案が出る |
| 構成の崩れ | 教えと実践が長い段落になり、X に貼りにくい |
| 禁止表現 | 出典なしの「仏陀の言葉」に近い書き方 |
| チェックの形骸化 | 人間用チェックリストが残るが、毎回人手で直す |
実際、初期の下書きでは 248字・217字 といった超過が発生しました(第3回で採点)。
書く担当 と 直す担当 を分ける動機はここにあります。
2体に分ける設計 — 文案と校正
3-1. 文案エージェントの責務
| やること | やらないこと |
|---|---|
| 曜日ローテーションに沿った題材調査 | X への投稿 |
| 投稿本文の作成 | 140字の 最終保証(校正に委ねる) |
social/x-drafts/YYYY-MM-DD.md の新規作成 | 過去ファイルの ルール検査 |
| 出典メモの記載 | status: posted の変更 |
正本: x-shuuchaku-agent-spec.md
起動: automation/x-daily/prompt.md
3-2. 校正エージェントの責務
| やること | やらないこと |
|---|---|
| 6項目チェックリストの実行 | 文案のゼロから新規作成 |
| 違反の修正(最大1回) | 題材の再調査 |
## 校正結果 の追記 | X API・自動投稿 |
char_count の再計測 | 投稿済みファイルの編集 |
正本: x-proofread-agent-spec.md
起動: automation/x-proofread/prompt.md
3-3. 連携の順序
文案エージェント → 校正エージェント → 人間(確認・投稿)
並列ではなく直列 にします。校正は「文案の出力ファイル」を入力とするため、順序が明確です。
spec と prompt の分担
| ファイル種別 | 文案 | 校正 |
|---|---|---|
| spec | テーマ・フォーマット・調査ルール | チェックリスト・修正優先順位 |
| prompt | 「今日1本、spec に従って作成」 | 「指定日の md を検査・修正」 |
ルールの変更は spec だけ を直し、prompt は薄く保つ — 第1回 の型どおりです。
ハーネス記事 で書いた「検証は別レイヤ」も、校正エージェントを 2体目として分離 する設計に対応します。
校正エージェントのチェック項目(第3回の評価基準)
| # | 項目 | 合格条件 |
|---|---|---|
| 1 | 文字数 | 140字以内(改行・タグ含む) |
| 2 | 構成 | 教え1文 + 実践1文 |
| 3 | 禁止表現 | 出典なしの「仏陀は〜」等なし |
| 4 | ハッシュタグ | 0〜1個 |
| 5 | URL | 本文に URL なし |
| 6 | 重複 | 直近30日と 同一概念 でない |
第3回では、この6項目の 初回合格率 を「精度」の代理指標にします。
全体フロー図
緑 = エージェント · オレンジ = 人間
flowchart TB
A1["① 文案エージェント<br/>調査・文案作成"]
A2["② 下書き md 保存"]
A3["③ 校正エージェント<br/>6項目チェック"]
A4["④ 修正・校正結果追記"]
H1["⑤ 人間が確認"]
H2{⑥ 手直し?}
H3["⑦ X に投稿"]
A1 --> A2
A2 --> A3
A3 --> A4
A4 --> H1
H1 --> H2
H2 -->|はい| H3
H2 -->|いいえ| H3
classDef agent fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px,color:#1a1a1a
classDef human fill:#fff3e0,stroke:#e65100,stroke-width:2px,color:#1a1a1a
class A1 agent
class A2 agent
class A3 agent
class A4 agent
class H1 human
class H2 human
class H3 human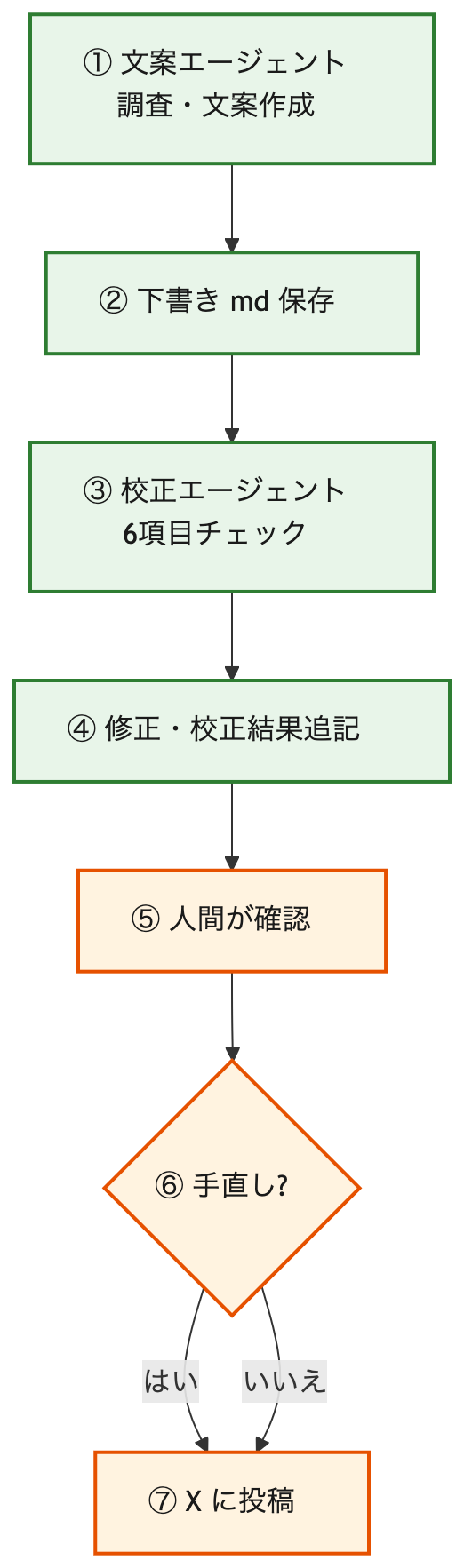
GitHub Actions で毎朝回す場合は、①の前に Actions 起動が入ります(運用記事)。設計上の エージェントの分業 は同じです。
まとめ
- サンプルは X日本語文案 — ルールが明確で校正効果を測りやすい
- 文案 は作る、校正 は直す — 責務を分離する
- 評価は 6項目チェックリスト で統一する
- 第3回で 校正なし(条件A)とあり(条件B) を比較する
第1回 の「ルール層」に、ここで 2体の役割分担 を足した形です。

コメント